
[데이터베이스] 인덱스
Updated: Categories: CS매우 중요한 인덱스에 대해 알아보자
인덱스
- 데이터베이스에서 테이블의 조회 속도를 향상시키기 위한 자료구조
- key-value 구조로 되어있으며 key에는 데이터 값을, value에는 데이터의 주소(PK/ROW-ID)를 저장한다
- 항상 정렬된 상태로 유지된다
장점
- 테이블의 조회 속도를 향상시킬 수 있다
- 기존 데이터 조회시 풀 테이블 스캔 -> 시간복잡도 : O(N)
- 인덱스 사용시 B+ Tree 스캔 -> 시간복잡도 : O(logN)
단점
- 데이터의 삽입/삭제/수정이 일어날때마다 인덱스 테이블에서 정렬이 일어남
- 인덱스 테이블은 원본 테이블의 10%에 해당하는 저장공간을 차지함
사용예시
- 규모가 큰 테이블
- 중복되는 데이터가 적은 컬럼 (== 카디널리티가 높은 컬럼)
- 조회가 많이 일어나고 삽입/삭제/수정은 적게 일어나는 컬럼
- 정렬 조회가 자주 일어나는 컬럼
동작원리
생성
- 테이블의 컬럼에 인덱스를 설정함
- 해당 컬럼에 대한 데이터를 정렬 -> 인덱스 테이블 생성
- key : 컬럼의 데이터
- value : PK(ROW-ID)
조회
- 인덱스 컬럼이 포함된 테이블에서 특정 데이터 조회
- 인덱스 테이블에서 데이터를 조회 -> PK 찾음
- 실제 테이블에서 PK로 row 찾음
삽입, 삭제, 수정
- 인덱스가 걸려있는 컬럼에 데이터 삽입/삭제/수정 일어남
- 인덱스 테이블에서 한번 더 데이터를 정렬해줘야 함
자료구조
Hash Table
- key-value 형태로 해시값을 사용하여 O(1) 속도로 데이터 탐색이 가능한 자료구조
- key : 컬럼 데이터를 해싱한 값
- value : 원본 데이터 주소
- 컬럼 데이터값을 해싱하기 때문에 등호(=)연산에만 특화되어 있음
- 여러 연산을 지원해야하는 쿼리문에 적합하지 않음
- 데이터베이스 인덱스의 자료구조로는 거의 사용되지 않음
B(Balance) Tree
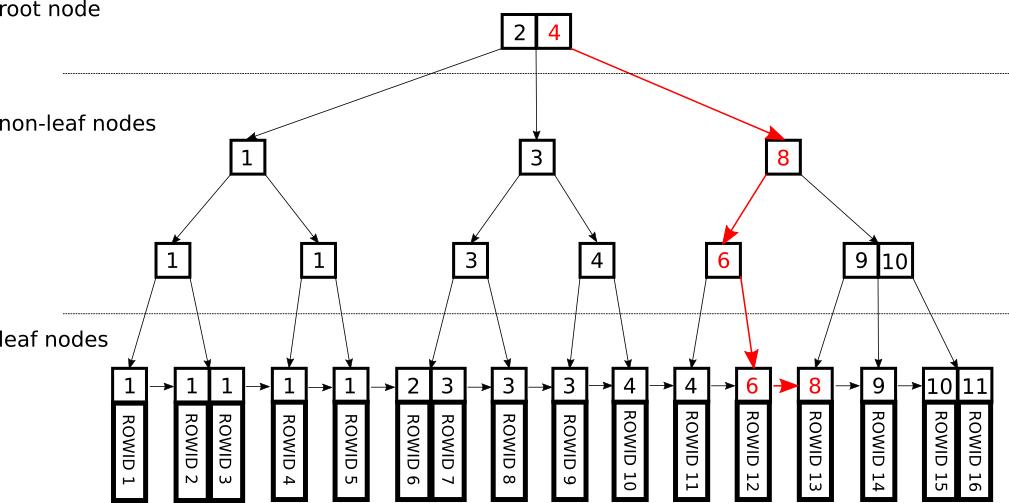
- 이진트리를 확장한 트리 자료구조
- 시간복잡도 : O(logN)
- root, branch(non-leaf), leaf 노드로 이루어져 있음
- root 노드부터 leaf 노드까지의 거리가 일정하다.
- root :
- branch :
- leaf :
- 하나의 노드에 많은 데이터를 저장가능
- DB에서 사용하기 적합함
B+ Tree
- B Tree를 확장한 구조
- branch 노드에 key만 저장하고, leaf 노드에서 key + data를 저장함
- 메모리를 확보함으로써 더 많은 key를 수용
- 하나의 노드에 더 많은 key를 담을 수 있기에 트리 높이가 낮아짐 -> cache hit 증가
- leaf 노드끼리 연결리스트로 연결되어 있음
- 한번의 선형탐색만 하면 되기에 B-tree보다 빠름

- InnoDB에서는 같은 레벨의 노드끼리 이중연결리스트로 연결되어있음
- leaf 노드에 도달하면 데이터의 물리 주소값을 획득
B vs B+

종류
클러스터드 인덱스
- DBMS가 자동으로 설정하는 인덱스
- 테이블에서 카디널리티가 가장 높은 컬럼을 선택하게 된다
- Primary Key
- Unique key
- Hidden Key(6byte) 생성
- 테이블당 한개, 컬럼 한개만 생성 가능
- 테이블이 물리적으로 정렬되어 있다
- 조회 성능이 좋지만 삽입/삭제/수정은 느림
넌클러스터드 인덱스
- 개발자가 직접 설정하는 인덱스
- 테이블당 여러개, 여러 컬럼으로 생성 가능
- 테이블당 인덱스 최대 수 : 64
- 인덱스당 최대 컬럼 수 : 16
- 테이블이 물리적으로 정렬되지 않고, 포인터를 사용해 논리적으로 행을 재배열함
- 조회 성능은 떨어지지만 삽입/삭제/수정은 빠름
- 유니크 인덱스
- 테이블 제약조건에 Unique를 걸면 자동으로 유니크 인덱스가 만들어진다 (MySQL)
- 멀티 컬럼 인덱스
- 여러 컬럼으로 이루어진 인덱스
- 컬럼의 카디널리티가 높은 순에서 낮은 순으로 구성하는게 성능이 좋음
- 인덱스에서 첫 번째로 설정된 컬럼은 반드시 사용되어야 함
참고링크
- https://kyungyeon.dev/posts/66
- https://zorba91.tistory.com/293